Content on Demand: l’Intelligenza Artificiale che crea contenuti audio originali ed esclusivi ora disponibile in beta test
A inizio dicembre 2023 è entrato in fase di beta test il servizio Content on Demand di cui ci eravamo occupati ad agosto.
Rispetto a questa estate il prodotto è stato applicato anche a settori differenti da quello strettamente radiofonico, come ad esempio nel caso di un’applicazione legata agli smart speaker e una agli annunci alla popolazione.
Vediamo in questo articolo qualche ulteriore dettaglio, come funziona in pratica e come partecipare alla fase di beta.
Beta Test
Beta test nel gergo informatico significa che un prodotto o servizio passa dalla fase “a uso interno” a una di test pubblico. Nel nostro caso, Content on Demand di 22HBG è dunque ora aperto a emittenti e sviluppatori che desiderino sperimentarlo, sapendo che potrebbero trovare alcune funzionalità ancora non completamente messe a punto.
Content on Demand
Ricordiamo innanzitutto di cosa si tratta. Content on Demand è un servizio sviluppato da 22HBG che permette di creare contenuti audio originali di qualità sulla base di specifici “prompt” tramite il supporto dell’Intelligenza Artificiale (IA) di Peperoni AI.
Come funziona
Utilizzeremo per questo esempio il caso di un’emittente radiofonica.
L’accesso avviene tramite web (dunque nessuna applicazione da installare) e l’interfaccia presenta pochi e intuitivi campi da riempire:
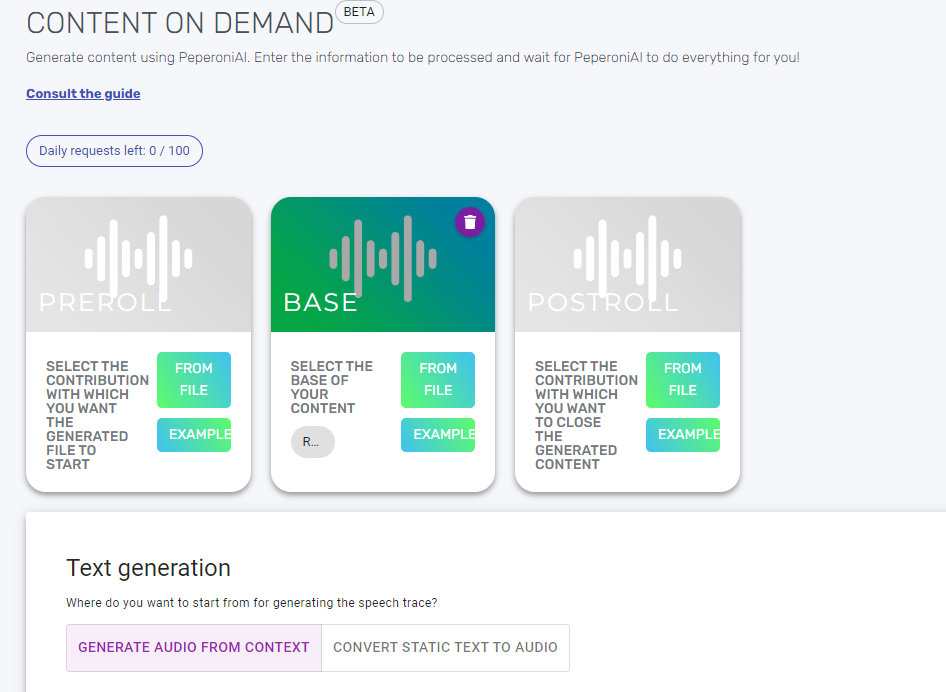
Preroll, Base e Postroll non sono ovviamente concetti che occorre spiegare ai lettori di questa testata.
Parliano invece del box in basso, “Text Generation”:
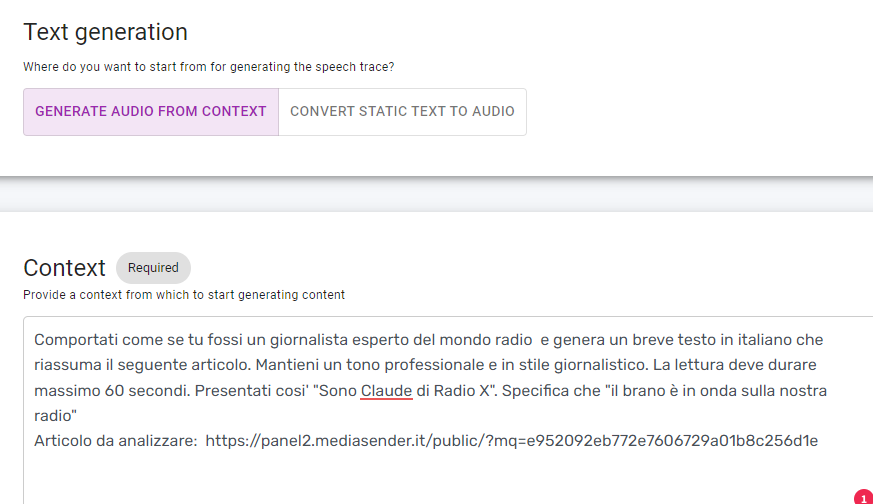
Text Generation
Qui si interagisce con la IA, fornendo alcune indicazioni generali (“comportati come se tu fossi un giornalista esperto..”) e alcune particolari (“genera un testo in italiano …”).
Si tratta del cosiddetto “prompt”, la richiesta che si fa alla IA. Generalmente occorre qualche iterazione per mettere a punto il messaggio esatto, chiarendo il comportamento desiderato con frasi quali “esprimiti in modo formale” oppure “non citare nomi di persone” o “termina dicendo ‘un saluto agli ascoltatori’ “. Ma si tratta di un’operazione da effettuare una sola volta in fase di messa a punto del sistema.
Speaker
Sono disponibili le voci di numerosi speaker artificiali: a oggi 506 combinazioni di lingua parlata e sesso dello speaker, generate tramite tecnologia Microsoft e tramite quella di Google.
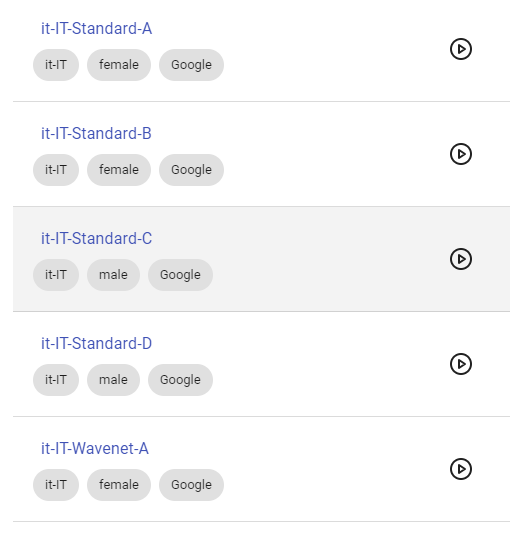
È possibile un preascolto basto su una frase standard, oppure si può’ generare un contenuto personalizzato, come nei due esempi che seguono:
Clip generato con voce google “it_standard_C” (nome provvisorio)
Stesso clip, ma genarato con voce “it_Wavenet-D” (nome provvisorio)
Workflow automatici
Fin ora abbiamo mostrato un utilizzo manuale dell’applicazione da parte di un operatore umano, ma è comunque possibile creare dei workflow automatizzati. Vediamo come.
 Feed RSS
Feed RSS
 Feed RSS
Feed RSSLa magia si chiama “feed RSS”, la versione “machine-readable” di ogni sito web. Nell’esempio che segue, abbiamo chiesto a Content on Demand di creare un clip sulla base delle ultime notizie di borsa recuperate da uno dei feed di cui parleremo tra breve, utilizzando il prompt seguente:
“Crea un audio clip di 60 secondi in base alla notizia contenuta nel feed RSS”
Questo il risultato
Automazione…
Fin qui i clip audio sono creati sotto la supervisione di un operatore umano. Ma Content on Demand prevede una totale automazione, con la possibilità di programmare la creazione di nuovi contenuti originali a intervalli predefinitili:
 …e integrazione
…e integrazione
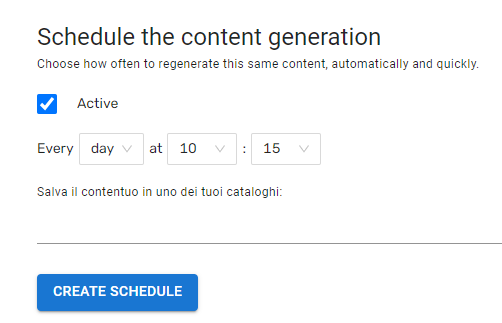 …e integrazione
…e integrazioneIn questo modo risulta semplice programmare il caricamento dei contenuti in specifiche location (cartelle) per la messa in onda automatica.
Si può andare oltre: 22HBG propone integrazioni personalizzate che connettono Content on Demand al sistema di automazione adottato dalla singola emittente.

Possibili utilizzi – Radio
Sono innumerevoli i campi di applicazione possibili. Si pensi ad esempio a una rubrica di aggiornamento in tempo reale sui dati di borsa: siti come it.investing.com, Wallstreetitalia o CNBC forniscono un’ampia serie di informazioni in tempo reale, tutte catturabili da Content on Demand. Facile dunque creare un automatismo che, in base al clock dell’emittente, recuperi le informazioni e crei in tutta autonomia il clip audio da inserire in programmazione.

Non solo radio

Abbiamo detto che Content on Demand è utile anche oltre i confini del mondo radiofonico. Sono infatti previsti – e di fatto già’ sperimentati in questi mesi – numerosi servizi basati sull’audio, dove messaggi indirizzati al grande pubblico o anche a utilizzatori specifici e diffusi da altoparlanti o smart speaker sono generati da Content on Demand in base alle informazioni recepite proprio tramite il meccanismo di feed che abbiamo visto.
Niente clonaggio voci
Per terminare, una nota sulla strategia di 22HBG riguardo le voci clonate. È oggi possibile – e di fatto funziona incredibilmente bene – creare una versione artificiale di un qualunque conduttore sulla base di poche decine di minuti di parlato originale.
Si è deciso per il momento di non implementare questa funzionalità: oltre i consueti motivi etici (e’ appena terminato un lungo sciopero di attori e autori di Los Angeles e la IA era uno dei temi delle rivendicazioni), la società ritiene che sia più opportuno utilizzare oggi queste tecnologie per creare prodotti e processi innovativi, piuttosto che per dubbi tentativi di rimpiazzo di personale qualificato.
Conclusioni
Avere in onda contenuti sempre aggiornati – anche durante la notte, anche durante le festività – è certamente un vantaggio competitivo per un’emittente. Cosi come lo è la possibilità creare e inventare contenuti originali e articolati sulla base di poche rapide indicazioni tutte le applicazioni che prevedono l’utilizzo di contenuti audio. Tutte funzionalità che – con un minimo di personalizzazione iniziale – sono implementabili tramite Content on Demand.
Nelle prossime settimane torneremo a parlare di Content on Demand analizzando alcuni case studies di questa fase iniziale di alpha test; chi desiderasse entrare nella fase di beta può invece scrivere a [email protected] (M.H.B. per FM-World)
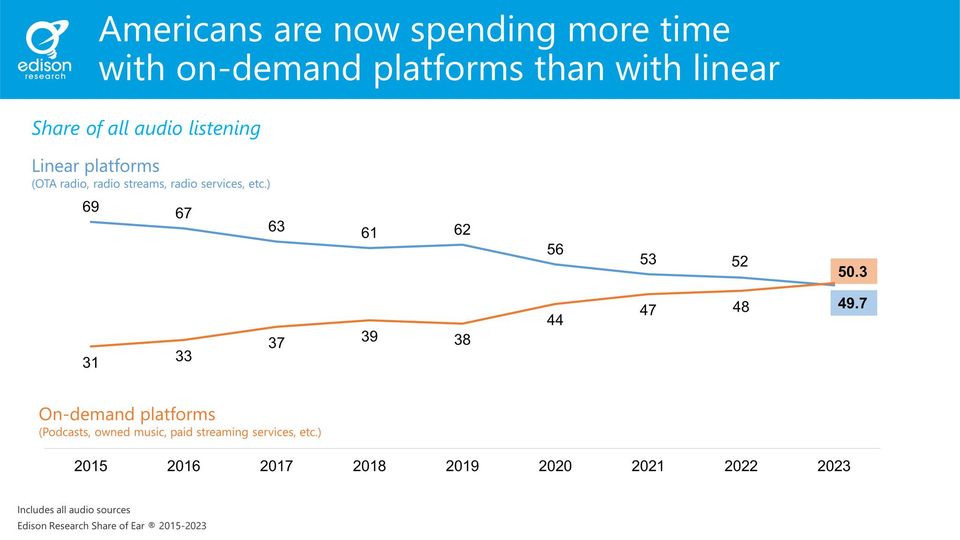 Il futuro della radiofonia al centro del dibattito su Facebook
Il futuro della radiofonia al centro del dibattito su Facebook
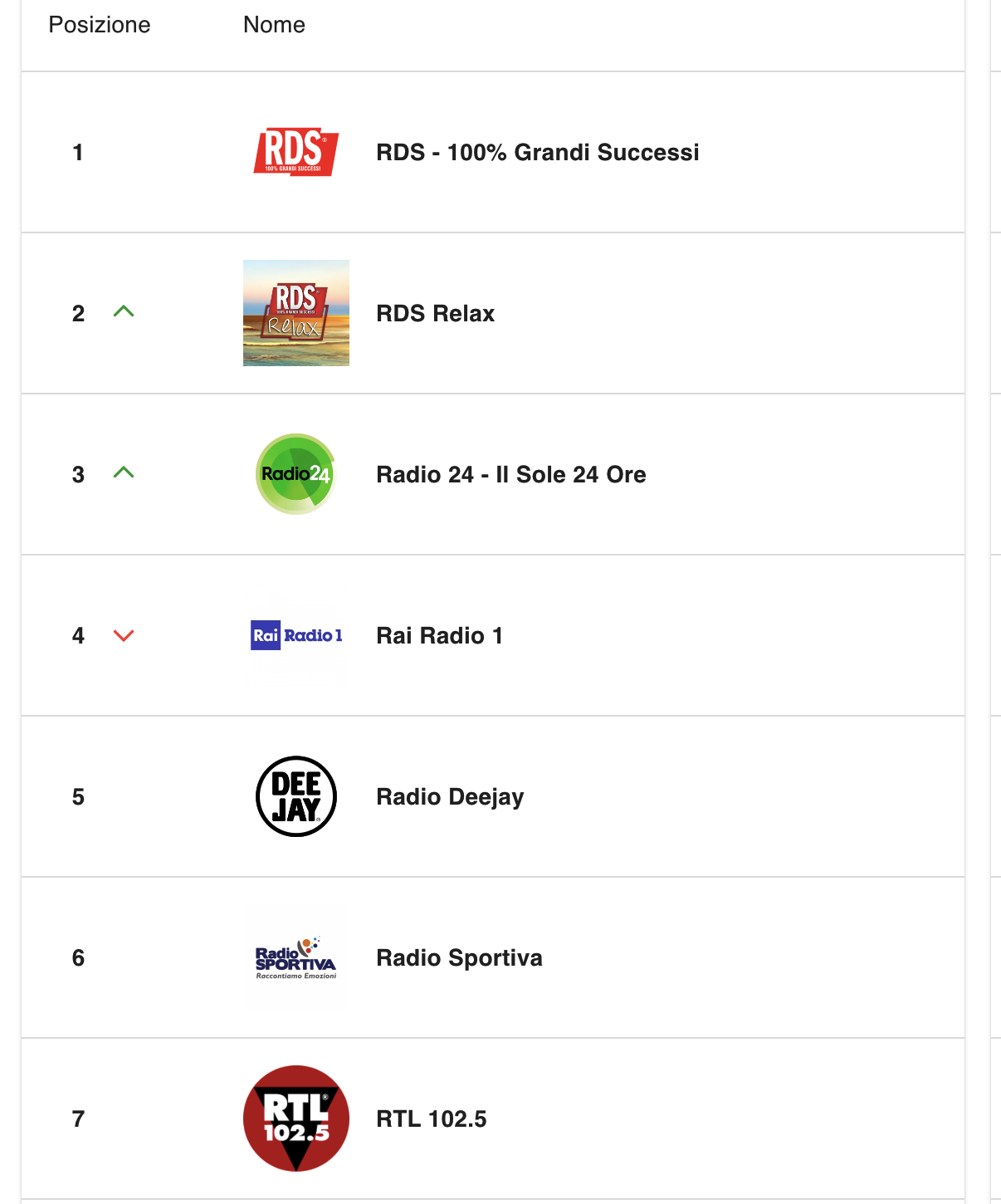 Le “chart” di FM-World al centro del dibattito sugli ascolti radiofonici
Le “chart” di FM-World al centro del dibattito sugli ascolti radiofonici