Il WSJournal (e qualche esperto di DataScience) ci aiutano a spiegare il vero algoritmo di Spotify
Si parla di tecnologia e di come funziona l’algoritmo di Spotify, in questo editoriale scritto per FM-world da Marco Barsotti.
Dopo tanti post in cui esperti o presunti tali ci spiegavano l’algoritmo di Spotify (battezzato da alcuni BaRT, Bandits for Recommendations as Treatments, il 15 aprile è stato pubblicato un articolo sullo stesso argomento da parte del Wall Street Journal. Unendo quanto spiegato da questa autorevole fonte ad alcuni interessanti notebook (in Python) di parte di studiosi di DataScience pensiamo di poter raccontare qualcosa di interessante.

Scettici?
Prima di buttarci nei dettagli una spiegazione. Siamo sempre stati scettici degli articoli online che “spiegavano” BaRT in quanto – a differenza di Facebook e di Netflix – il blog dell’engineering di Spotify (che è questo) non ha mai citato nulla di nome BaRT. Abbiamo visto articolo sulle proprietà dell’ algoritmo di Poisson per la stima dei quartili in test A/B o anche una descrizione tutta da leggere (non mancate, qui) sull’aura musicale di ciascuno di noi. Ma di BaRT niente. Ma passiamo all’articolo del Journal.

Echonest
Le basi dell'”algoritmo” vengono dall’acquisizione da parte di Spotify di The Echonest avvenuta nel 2014: si tratta di un’azienda nata come spinoff del MIT Media Lab (quello di Negroponte e del suo One Laptop per Child).
Echonest non analizzava solo i brani in quanto tali: in un post del 2013, subito prima l’acquisizione, veniva spiegato chiaramente: “Indicizziamo e analizziamo oltre 10 milioni di nuovi blog post, discussioni sui social media e recensioni musicali quotidiane.
Applichiamo poi tecniche di Machine Learning e Natural Language Processing per contestualizzare queste discussioni e identificare trend musicali”.
Oltre i metadati
Troverete il resto della spiegazione qui. Ed è quel database, per cosi’ volerlo chiamare, che ha posto le fondamenta per il sistema di raccomandazioni attuale.
Collaborative filtering
Il primo passo oggi è un processo detto “collaborative filtering“. Tra i suoi obiettivi, spiega al WSJ Ziad Sultan “vice presidente della personalizzazione” di Spotify, quello di identificare affinità tra brani e podcast (tra brani e podcast!) osservandone i posizionamenti relativi nelle playlist di milioni di utenti.
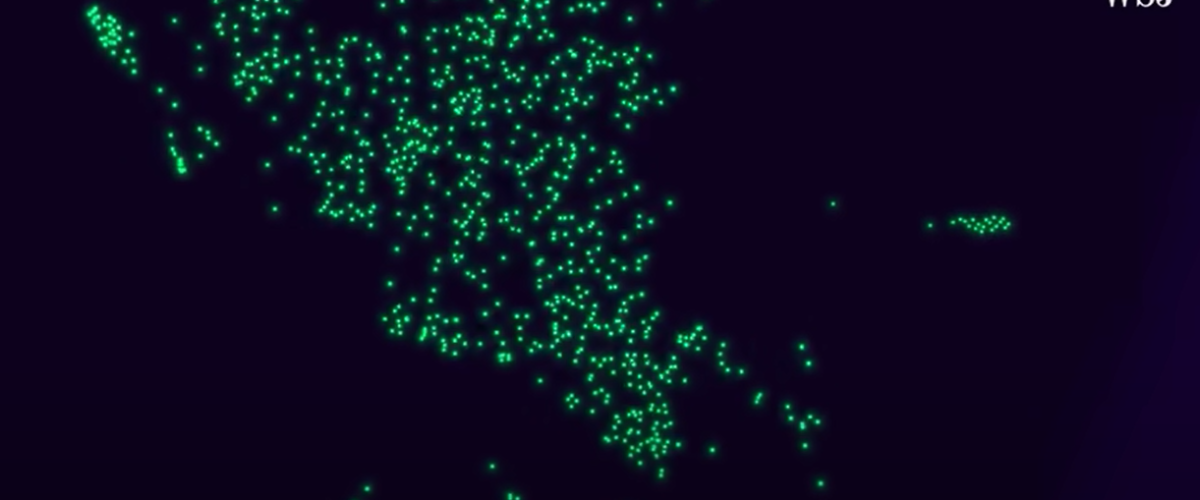
Spazio n-dimensionale
Questi oggetti (brani e podcast) sono inseriti nello spazio n-dimensionale che possiamo vedere in versione semplificata (3D) qui sopra: la distanza cartesiana tra i punti rappresenta le affinità.
Interessante notare come questo sia esattamente lo stesso criterio usato dai vari LLM come ChatGPT per clusterizzare i concetti (o meglio, token e parole):
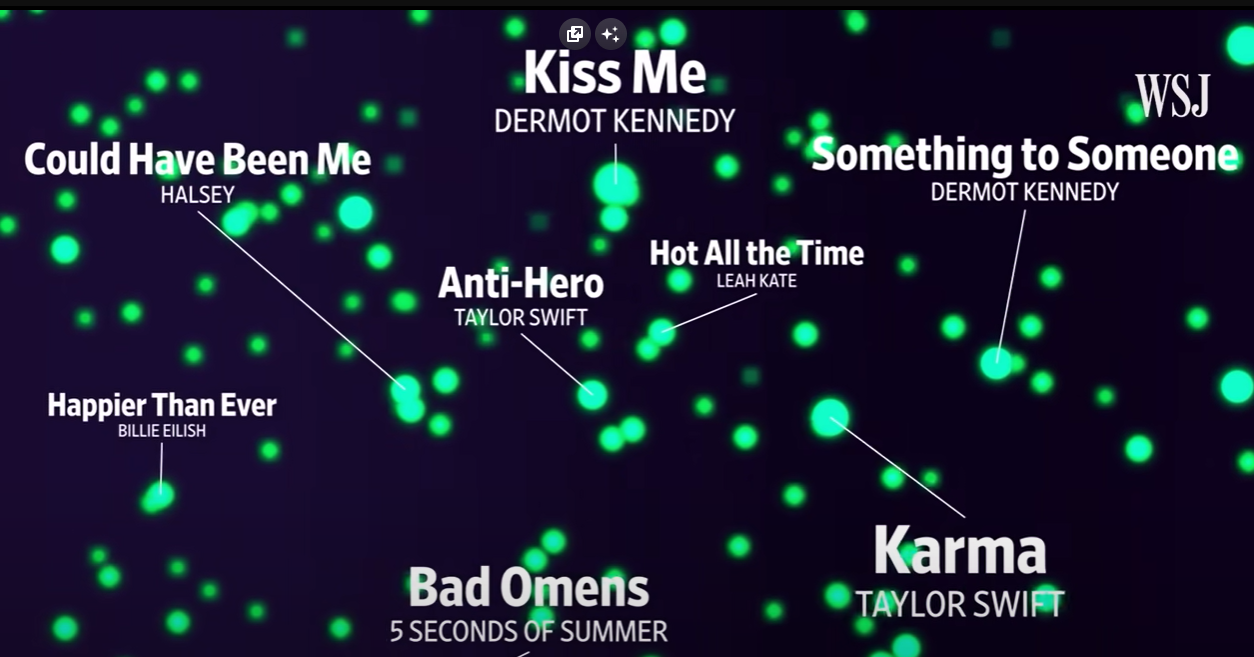
Natale
A Natale siamo tutti più buoni, tranne pero’ questi spazi n-dimensionali che divengono nocivi. Basta pensare al tormentone “All I Want for Christmas Is You” di Carey che a partire da inizio dicembre si trova prossimo a praticamente tutti gli altri brani, tra cui lo scorrelatissimo “Silent Night“. E apparentemente in Italia anche a Quevedo (e agli Wham).

Terremoti
Un effetto poco gradevole già a dicembre, figuriamoci da gennaio in poi. E – detto per inciso – a chi scrive è capitato “su un noto social” di vendere per due settimane una quantità irragionevole di influencer turche musulmane intente (crediamo) a spiegare qualche concetto trascendente.
La spiegazione stava nella “deduzione” del di lui “algoritmo” di un nostro interesse per una religione avendo avuto la colpa di visualizzare un po’ troppi video relativi al terremoto in Turchia.

Content Based Filtering
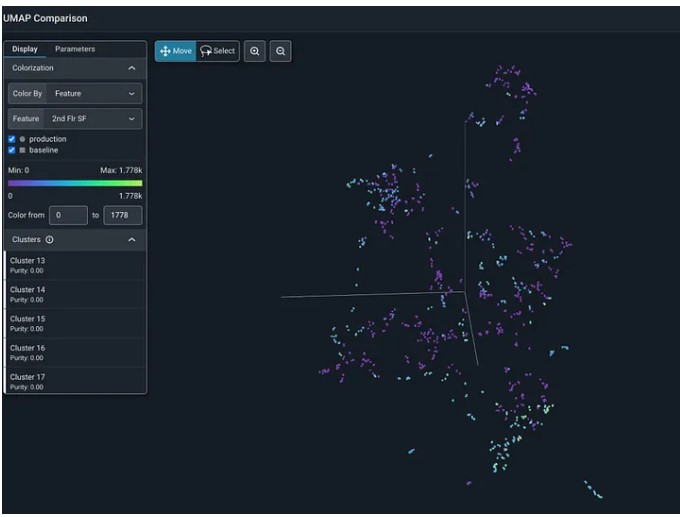
Andiamo avanti. Il passo successivo è il Content Based Filtering. L’idea è di associare un numero decimale (“float32”) a ciascuno dei seguenti parametri per ogni brano: loudness, tempo, danceability, energy, speechiness, acousticness, instrumentalness, liveness, valence, e duration. Con un po’ di passaggi si ottiene un vettore associato a ogni playlist:
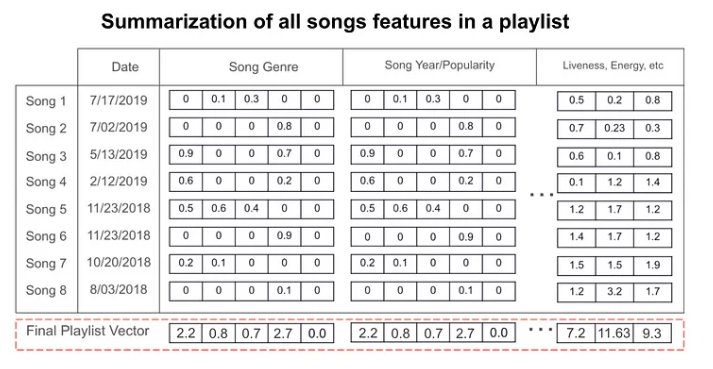
con il risultato all’immagine seguente (la playlist di base è quella a sinistra, mentre le due a destra sono generate da due differenti algoritmi, il primo dei quali è appunto quello di Spotify). Senza dubbio i tanti lettori di FM-World esperti di clock e playlist potranno darcene un giudizio ragionato.
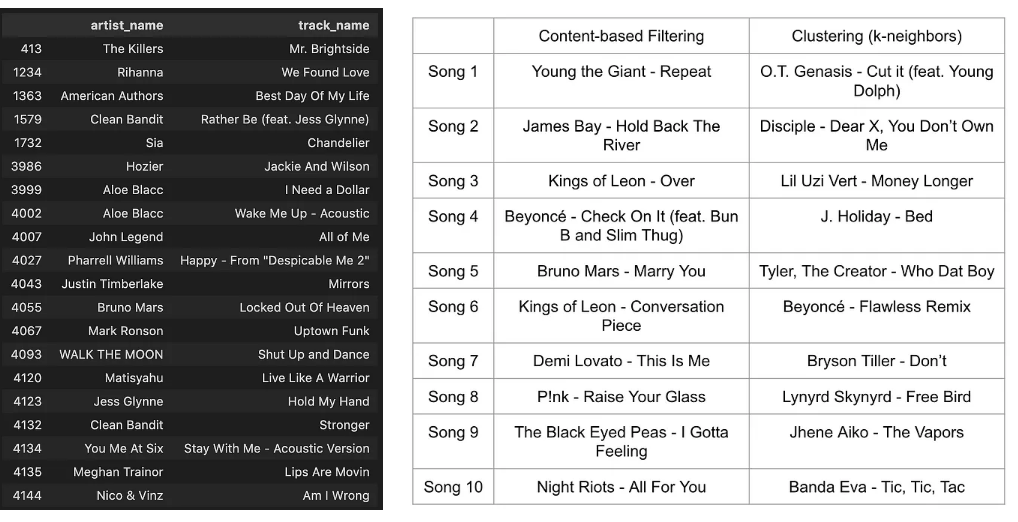
Non ditelo a nessuno, ma…
…Ma è possibile utilizzare questo sistema anche per creare playlist per le nostre emittenti: è tutto disponibile qui.
SIA vs Avicii
A titolo di curiosità, ecco di seguito i parametri che abbiamo trovato confrontando i parametri di due splendidi ma diversi brani: la versione di SIA di “I Go To Sleep” (a sinistra) con “Seek Bromance” di Avicii/Tin Berg (i parametri sono in stile JSON, dunque nome-parametro : valore). Ad esempio Avicii ha una “danceability” di 0,49 mentre SIA solo di 0,43.
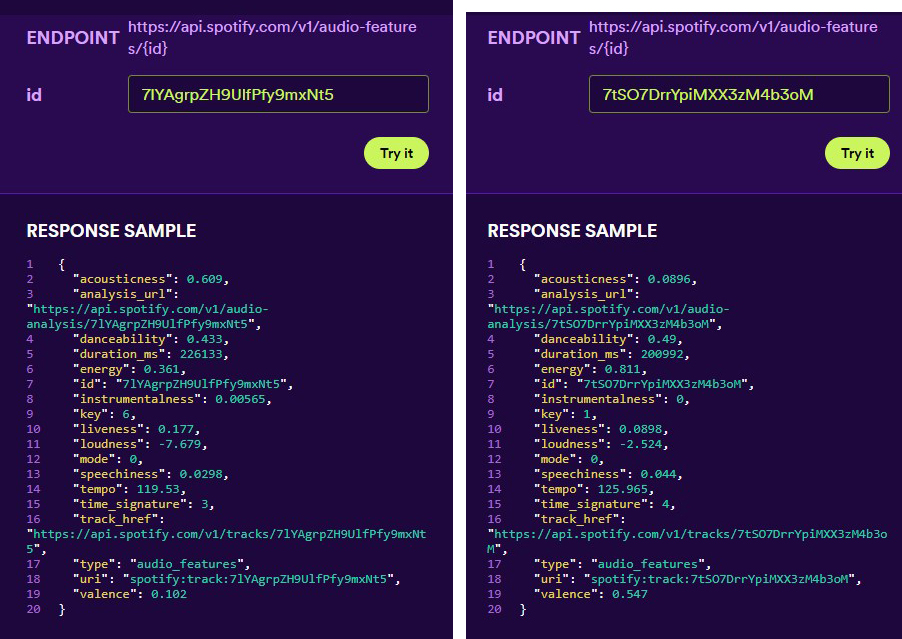
Recensioni
Questi dati, ricavati da un’analisi dei brani stessi, sono poi integrati con attributi e parole chiave utilizzate nelle varie recensioni fatte da critici (siti ufficiali) e normali ascoltatori (blogs e reddit): e qui ritroviamo, appunto, il database di The Echonest.
Politically-Correct-ness
C’era da attenderselo di questi tempi: l’articolo del Journal non poteva esimersi da terminare con una “messa in guardia” contro l’attacco alla “diversità” possibile tramite questi sistemi di IA.
Ecco la spiegazione: “Se un ascoltatore ha nella sua playlist una predominanza di brani cantati da uomini allora le playlist (per terzi) create sulla base di quella rischiano anch’esse di aver un bias “anti-femminile” (!) creando un possibile feedback loop che amplificherà l’aberrazione.

Soul Music
E quindi non possiamo che concludere con una nota positiva: agli esordi di Radio Milano International in tanti ci eravamo appassionati della Motown e della Soul Music: il nostro personale bias era (e in parte è, avendo ancora sull’iPhone alcune compilation dell’epoca) decisamente pro-black (scusate l’inglese), dunque nessuno potrà mai darci dei razzisti.
Orgogliosi possiamo oggi affermarlo: stavamo lodevolmente cercando di costruire un mondo con una maggiore “inclusion“. (Marco Barsotti per FM-World)