Radio totalmente gestite dalla IA? Content on Demand propone un approccio differente, immediatamente utilizzabile e che costruisce sull’esistente
Content on Demand è uno strumento che – lungi dal rimpiazzare speaker e redattori – permette di creare nuovi contenuti anche in modo altamente automatizzato. Cerchiamo di capire di cosa si tratta sulla base di un’esperienza concreta di utilizzo
Dopo il lancio di ChatGPT a fine novembre 2022 molti – noi compresi – si sono fatti prendere dall’entusiasmo, prevedendo un futuro popolato di radio gestite da IA dove i contenuti sono generati da un LLM (Large Language Model, come GPT 3.5, Claude di Anthropic o LLama-2 di Meta), mentre le le voci sono generate da altri modelli che hanno appreso il modo di parlare di speaker reali.
Not so fast
Sono passati nove mesi: pensiamo di aver capito qualcosa in più e poter posizionare correttamente la IA come una risorsa addizionale, più che un cambio totale dell’impostazione delle emittenti con conseguente riduzione degli organici.
Si tratta ovviamente di una conclusione personale e provvisoria in quanto, inevitabilmente, quello che pensavamo fosse fattibile a fine 2022 lo sarà comunque in prospettiva.
Ma andiamo per gradi.
Patrizia
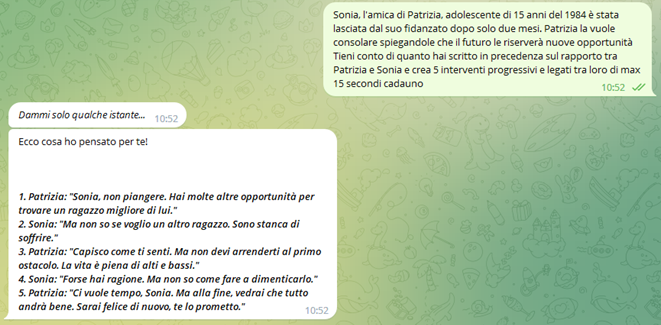
Cominciamo con un early adopter, la società editrice di 70-80.it. Praticamente subito inventa un format radiofonico, il Diario di Patrizia, dove le vicende di un’adolescente degli anni 70/80 sono create da GPT 3.5 tramite il front-end di PeperoniAI.
Per arrivare al risultato desiderato si parte da una serie di racconti scritti da un copywriter umano: vicende di ragazzi, innamoramenti e problemi in famiglia.
Questi script non sono destinati a essere trasmessi, ma ad allenare la IA. Successivamente vengono fornite s Peperoni specifiche istruzioni, quali:
Numera le storie, identificandole con un numero progressivo
Usa uno slang da ragazzi degli anni ’80
Scrivi storie brevi (una decina di righe) adatte a essere lette in radio e non troppo complicate.
Se possibile storie divertenti anche se l’obietttivo non è far ridere
Prompt e risultati
Ecco un esempio di risultato ottenuto in una prima fase del progetto chiedendo di “creare tre storie che siano autoconclusive, che significa che ogni blocco di episodi si riferiscono ad un evento particolare, dove la situazione sia “visita del museo della scienza e della tecnica di Milano“
Storia 1 – Generata da GPT 3.5 e Peperoni
Oggi la prof di matematica ci porta in gita al Museo della Scienza. Secondo me sarà una palla mortale, però Luca ha detto che verrà anche lui con la sua classe, quindi spero di rivederlo! L’unica è seminare quel rompiscatole di Franco, se no mi seguirà come un cagnolino per tutta la visita…
Storia 2 – Generata da GPT 3.5 e Peperoni
Appena arrivati al museo, come previsto Franco mi si è attaccato subito. Per fortuna dopo un po’ l’ho seminato di nuovo al padiglione dedicato all’energia. Poco dopo ho incontrato Luca, era con i suoi amici. Ci siamo scambiati un’occhiata e un sorriso, che imbarazzo! Più tardi ci siamo ritrovati da soli all’esposizione delle macchine volanti. Luca mi ha preso la mano, che emozione! Forse questa gita non sarà poi così noiosa…
Ed ecco il risultato andato in onda (dove come si puo’ notare la speaker ha aggiunto qualcosa di suo):
Supercomputer mancanti
Il progetto prevedeva che la IA generasse anche un clone della voce della speaker, ma i fatti hanno dimostrato che ricreare una voce simile e credibile in italiano non e’ ancora possibile.
Non per problemi tecnici: le voci inglesi sono clonate in modo praticamente perfetto.

Il tallone d’Achille è la mancanza di risorse nazionali (grossi server con migliaia di GPU) dedicabili alla comprensione e simulazione delle voci italiane. E questo è un punto nodale su cui dovremo necessariamente tornare.
Kai
In germania qualcuno ha voluto andare oltre, creando una radio totalmente gestita da una IA, che ha denominato KAI. È il caso di Absolute Radio AI, il cui gestore ha recentemente dichiarato a Newslinet che “Gran parte del lavoro di Absolut Radio AI è gestito dal nostro sito, che invia la richiesta a ChatGPT e controlla e ottimizza nuovamente la risposta. La piattaforma esegue il flusso di lavoro completamente da sola; tuttavia per i primi mesi gli umani verificheranno tutti i testi e ascolteranno i vocali prima della messa in onda.”
Reality Check
Abbiamo fatto un doveroso reality check ascoltando la radio.
Ricordiamo poco del tedesco appreso al tempo del liceo, ma ci sentiamo di dire che il format scelto è intelligente: musica con interventi che parlano… della musica. In pratica la IA racconta qualcosa sui brani o gli artisti in onda, cosa fattibile senza troppi rischi di “allucinazioni” se il modello utilizzato e’ stato (come ipotizziamo) fine-tuned sulla storia della musica.

Le voci sintetiche tedesche sono credibili e il risultato – privo del tallone d’achille di molte radio, il famoso “e voi, come lo prendete il caffe’? scriveteci...” – molto gradevole. Anzi: sorprendentemente buono.
Voci sintetiche credibili
Ma veniamo al punto. Come dicevamo, il problema principale ad oggi, agosto 2023, sono le voci italiane, che suonano ancora vagamente artificiali (a differenza di quelle tedesche di Absolute Radio AI).
Nei primi due mesi di vita di Radio Nizza abbiamo avuto accesso e potuto sperimentare il nuovo servizio “content on demand“ di 22HBG, per il quale disponiamo di uno speciale accesso.
Arrivando alla conclusione che Content on Demand può efficacemente integrare il lavoro delle redazioni e degli speaker per i servizi quali quelli legati all’attualità ed eventualmente connettibili programmaticamente a feed specifici.
Content on Demand
Content on Demand, ricordiamo, è un servizio in cloud realizzato da 22HBG sulla base di quanto già sviluppato per Peperoni e dedicato alla creazione di interventi audio sulla base di prompt.
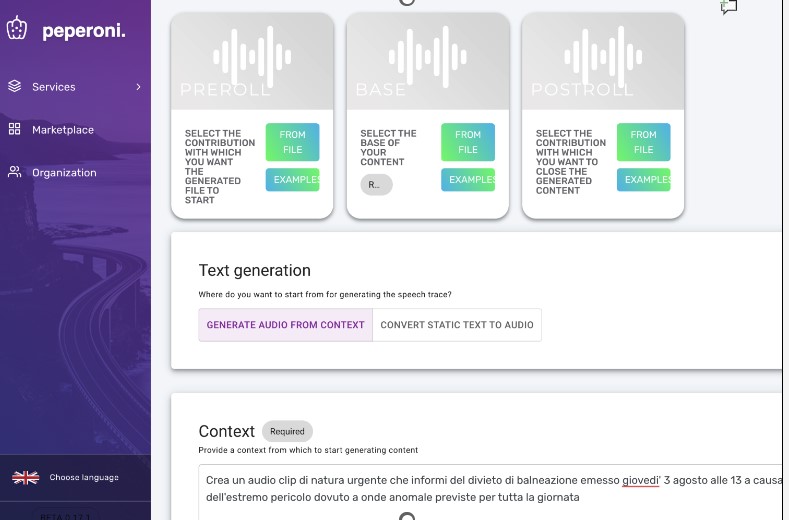
Come si vede nella schermata, è possibile caricare un preroll (nel nostro caso da parte della voce ufficiale di Radio Nizza) e un sottofondo (nel nostro caso il suono di una macchina per scrivere)
Dopodiché’ nell’area “Context” si procede ad inserire il proprio prompt (argomento complesso su cui torneremo) per vedersi creare, in pochi secondi, un clip completo, pronto per essere verificato e mandato in onda.
Ligne d’Azur
Abbiamo detto che Content on Demand può efficacemente integrare il lavoro delle redazioni e degli speaker per i servizi legati all’attualità. Cosa intendiamo dire?
Spieghiamoci con un esempio. La redazione confeziona ogni settimana contenuti ricchi, l’agenda degli eventi della Costa Azzurra o le news del giorno. Ma non può certo essere presente 24 ore su 24 per monitorare allerte o eventi puntuali, che sono però disponibili online.
Facciamo l’esempio del Tram di Nizza: ultramoderno, funzionante a batteria e non tramite linea aerea e altamente computerizzato. E di conseguenza sempre bloccato per ogni genere di problema (cosa che non accade agli storici serie 1500 di Milano).
Per ovviare al problema, il feed Twitter di ligne d’Azur (il servizio di trasporto pubblico di Nizza) viene aggiornato in tempo reale, come in questo caso:
⚠️Info trafic
En raison d’un éboulement, la ligne 90 est modifiée le jeudi 3 août 2023. 🚌
Plus d’informations ➡️ https://t.co/SC1JWjqW9E pic.twitter.com/vhKMwwlPjz
— Lignes d’Azur (@lignesdazur) August 2, 2023
Ed ecco il punto. Fornendo a Content on Demand il messaggio (catturato tramite uno script python) e precedendolo da un prompt specifico (sempre confezionato via Python) possiamo creare automaticamente un intervento radiofonico, inviando a Content on demand il prompt completo seguente:
Prompt: Crea un messaggio per Radio Nizza di natura urgente che informi – traducendo in italiano – di quanto segue: “En raison d’un éboulement, la ligne 90 est modifiée le jeudi 3 août 2023.”
Ed ecco il risultato messo in onda il 3 agosto (il contenuto inizia al secondo 14):
il cui testo è il seguente:
“Buongiorno a tutti i nostri ascoltatori. Abbiamo un annuncio urgente da fare riguardo alla linea 90. A causa di una frana, la linea 90 subirà delle modifiche giovedì 3 agosto 2023. Vi invitiamo a tenerne conto per i vostri spostamenti. Vi aggiorneremo con ulteriori informazioni non appena disponibili. Grazie per la vostra attenzione e buona giornata a tutti!”

Versione francese

Per la versione francese non è stato necessario alcun lavoro redazionale: è stato sufficiente nel prompt specificare “in francese”:
Prompt: Crea un messaggio per Radio Nizza di natura urgente che informi – in francese – di quanto segue: “En raison d’un éboulement, la ligne 90 est modifiée le jeudi 3 août 2023.”
Questo l’ottimo risultato, ottenuto in seconda battuta (la spiegazione tra poco):
Il testo:
Chers auditeurs de Radio Nizza, Nous avons une nouvelle urgente à vous annoncer. En raison d’un éboulement, nous devons vous informer que la ligne 90 sera modifiée ce jeudi 3 août 2023. Cette situation imprévue nous oblige à apporter des changements à l’itinéraire habituel de la ligne 90. Des mesures de sécurité sont en cours pour évaluer les dégâts et rétablir la situation normale dans les plus brefs délais. Nous vous recommandons de prendre vos dispositions pour éviter tout désagrément lors de vos déplacements. Il est possible que des retards ou des modifications temporaires soient nécessaires sur cette ligne. Veuillez suivre les instructions données par le personnel de la compagnie de transports en commun pour connaître les alternatives possibles. Nous comprenons que cela peut causer des désagréments et nous nous excusons pour les inconvénients que cela pourrait vous causer. Nous mettons tout en œuvre pour minimiser les perturbations et rétablir la situation normale dans les plus brefs délais. Restez à l’écoute de Radio Nizza pour les dernières mises à jour concernant cette situation. Nous vous tiendrons informés de tout développement ou changement concernant la ligne 90. Nous vous remercions de votre compréhension et de votre coopération. Prenez soin de vous et soyez prudents lors de vos déplacements. C’était un message urgent de Radio Nizza.
Francesismi
Come si vede il messaggio risultato è lunghissimo, tanto da obbligarci ad accorciarlo reiterando la richiesta a Peperoni preceduta da “ripeti il testo precedente accorciandolo del 50%“
La ragione è tanto ridicola quanto interessante: i francesi – lo possiamo ormai affermare per esperienza diretta – tendono ad essere molto cerimoniosi nello scrivere e parlare, trasformando anche comunicazioni brevi in discorsi lunghissimi. La IA, trainata su questo stile, ha dunque allungato a dismisura il messaggio, obbligandoci – appunto – alla seconda iterazione.
Versione Inglese
Infine, medesima operazione con l’inglese:
Il cui testo equivalente e’
Attention all listeners of Radio Nizza, we have an urgent message to inform you about a recent incident affecting the transportation services in the region. Due to a landslide, we regret to inform you that there will be modifications to the Line 90 on Thursday, August 3, 2023. These modifications are necessary for the safety of our passengers and to ensure smooth operations. We apologize for any inconvenience caused by this unexpected event. It is important to note that alternative arrangements will be made to minimize disruption to your travel plans. We advise all passengers who usually rely on Line 90 to check for the updated schedules and routes on our website or contact our customer service hotline for further information.
Sviluppi in Corso
Per quanto riguarda le voci in italiano, abbiamo parlato con il responsabile dello sviluppo di 22HBG che è al lavoro per la versione successiva di Content on Demand. Tra le altre cose, questa potrebbe prevedere delle opzioni in grado di modificare il “mood” o il “tono” della voce: tramite prereset sarà dunque possibile fare in modo che la voce artificiale parli in modo neutro (stile BBC World Service, per intenderci) o enfatico (come quello spesso adottato dai conduttori nei programmi musicali).
Ultima nota
Ultima nota: avete letto più sopra il responsabile di Absolute Radio AI affermare che “per i primi mesi gli umani verificheranno tutti i testi”.
Ebbene il nostro consiglio è di continuare a verificare l’output non “per i primi tempi” ma fino a che “i futuri sistemi AI che emulano il “super IO” umano – modelli addizionali che controllano a valle il lavoro della IA – siano in grado di rigettare contenuti non appropriati, allucinati o semplicemente “poco radiofonici” (M.H.B. per FM-World)